Since my Sunday post What Harvard and MIT could learn from the University of Phoenix about analytics, there have been a few comments with a common theme about Harvard and MIT perhaps withholding any learner-centered analytics data. As a recap, my argument was:
Beyond data aggregated over the entire course, the Harvard and MIT edX data provides no insight into learner patterns of behavior over time. Did the discussion forum posts increase or decrease over time, did video access change over time, etc? We don’t know. There is some insight we could obtain by looking at the last transaction event and number of chapters accessed, but the insight would be limited. But learner patterns of behavior can provide real insights, and it is here where the University of Phoenix (UoP) could teach Harvard and MIT some lessons on analytics.
Some of the comments that are worth addressing:
“Non-aggregated microdata (or a “person-click” dataset, see http://blogs.edweek.org/edweek/edtechresearcher/2013/06/the_person-click_dataset.html ) are much harder (impossible?) to de-identify. So you are being unfair in comparing this public release of data with internal data analytic efforts.”
“Agreed. The part I don’t understand is how they still don’t realize how useless this all is. Unless they are collecting better data, but just not sharing it openly, hogging it to themselves until it ‘looks good enough for marketing’ or something.”
“The edX initiative likely has event-level data to analyze. I don’t blame them for not wanting to share that with the world for free though. That would be a very valuable dataset.”
The common theme seems to be that there must be learner-centered data over time, but Harvard and MIT chose not to release this data either due to privacy or selfish reasons. This is a valid question to raise, but I see no evidence to back up these suppositions.
Granted, I am arguing without definitive proof, but this is a blog post, after all. I base my argument on two points – there is no evidence of HarvardX or MITx pursuing learner-centered long-running data, and I believe there is great difficulty getting non-event or non-aggregate data out of edX, at least in current forms.
Update: See comments starting here from Justin Reich from HarvardX. My reading is that he agrees that Harvard is not pursuing learner-centered long-running data analysis (yet, and he cannot speak for Stanford or MIT), but that he disagrees about the edX data collection and extraction. This does not capture all of his clarifications, so read comments for more.
Evidence of Research
Before presenting my argument, I’d again like to point out the usefulness of the HarvardX / MITx approach to open data as well as the very useful interactive graphics. Kudos to the research teams.
The best places to see what Harvard and MIT are doing with their edX data are the very useful sites HarvardX Data & Research and MITx Working Papers. The best-known research released as a summary report (much easier to present than released de-identified open dataset) is also based on data aggregated over a course, such as this graphic:
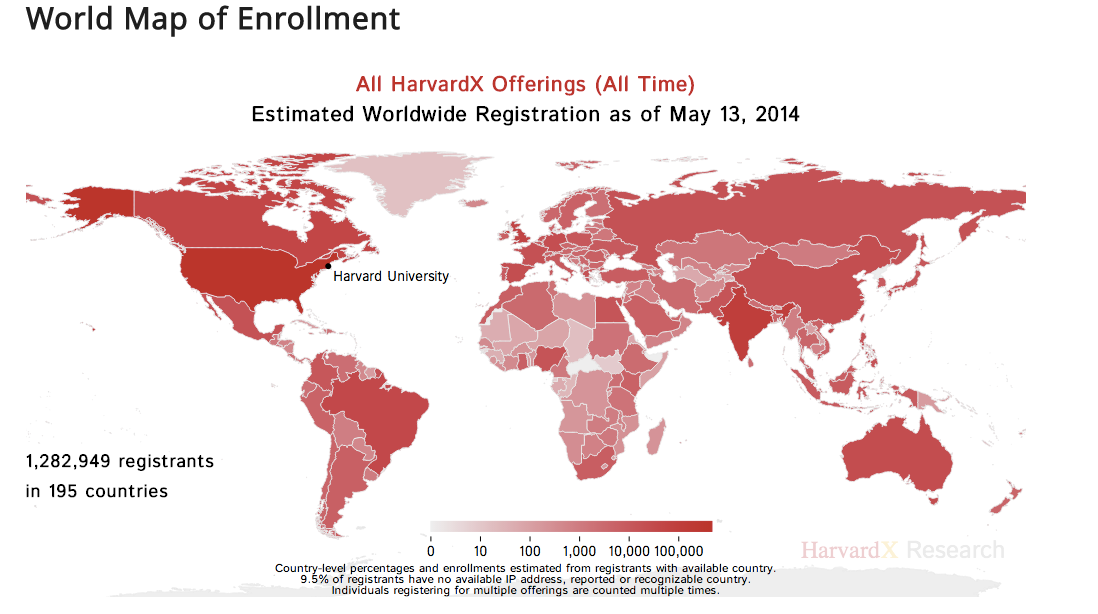
Even more useful is the presentation HarvardX Research 2013-2014 Looking Forward, Looking Back. In this presentation, there is a useful presentation of the types of research HarvardX is pursuing.
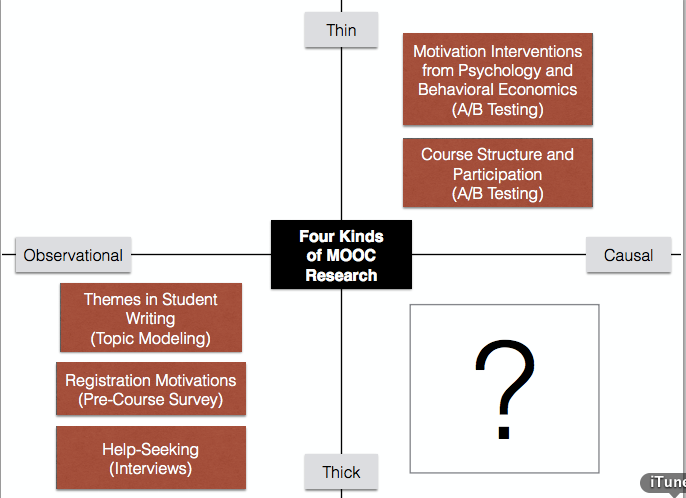
None of these approaches (topic modeling, pre-course survey, interviews, or A/B testing) look at learner’s activities over time. They are all based on either specific events with many interactions (discussion forum on a particular topic with thousands of entries, video with many views, etc) or subjective analysis on an entire course. Useful data, but not based on a learner’s ongoing activities.
I’d be happy to be proven wrong, but I see no evidence of the teams currently analyzing or planning to analyze such learner data over time. The research team does get the concept (see the article on person-click data):
We now have the opportunity to log everything that students do in online spaces: to record their contributions, their pathways, their timing, and so forth. Essentially, we are sampling each student’s behavior at each instant, or at least at each instant that a student logs an action with the server (and to be sure, many of the things we care most about happen between clicks rather than during them).
Thus, we need a specialized form of the person-period dataset: the person-click dataset, where each row in the dataset records a student’s action in each given instant, probably tracked to the second or tenth of a second. (I had started referring to this as the person-period(instantaneous) dataset, but person-click is much better). Despite the volume of data, the fundamental structure is very simple. [snip]
What the “person-period” dataset will become is just a roll-up of person-click data. For many research questions, you don’t need to know what everyone did every second, you just need to know what they do every hour, day or week. So many person-period datasets will just be “roll-ups” of person-click datasets, where you run through big person-click datasets and sum up how many videos a person watched, pages viewed, posts added, questions answered, etc. Each row will represent a defined time period, like a day. The larger your “period,” the smaller your dataset.
All of these datasets use the “person” as the unit of analysis. One can also create datasets where learning objects are the unit of analysis, as I have done with wikis and Mako HIll and Andres Monroy-Hernandes have done with Scratch projects. These can be referred to as project-level and project-period datasets, or object-level and object-period datasets.
The problem is not with the research team, the problem is with the data available. Note how the article above is referencing future systems and future capabilities. And also notice that none of this “person period” research is referenced in current HarvardX plans.
edX Data Structure
My gut feel (somewhat backed up by discussions with researchers I trust) is that the underlying data model is the issue, as I called out in my Sunday post.
In edX, by contrast, the data appears to be organized a series of log files organized around server usage. Such an organization allows aggregate data usage over a course, but it makes it extremely difficult to actually follow a student over time and glean any meaningful information.
If this assumption is correct, then the easiest approach to data analysis would be to look at server logs for specific events, pull out the volume of user data on that specific event, and see what you can learn; or, write big scripts to pull out aggregated data over the entire course. This is exactly what the current research seems to do.
Learner-Centered Data Analysis Over Time
It is possible to look at data over time, as was shown by two Stanford-related studies. The study Deconstructing Disengagement:Analyzing Learner Subpopulations in Massive Open Online Courses. looked at specific learners over time and looked for patterns.
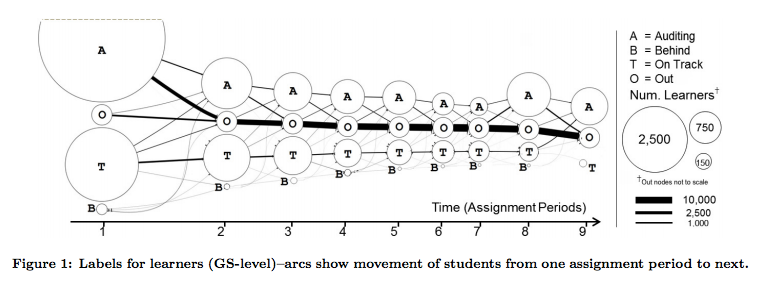

In both cases, the core focus was learner activity over time. I believe this focus is a necessary part of any learning analytics research program that seeks to improve teaching and learning.
What is interesting in the EDUCAUSE article is that the authors used Stanford’s Class2Go platform, which is now part of OpenEdX. Does this mean that such data analysis is possible with edX, or does it mean that it was with Class2Go but not with the current platform? I’m not sure (comments welcome).
I would love to hear from Justin Reich, Andrew Ho or any of the other researchers involved at HarvardX or MITx. Any insight, including corrections, would be valuable.
Hi All,
I can clarify some things here.
Why just person-course?
Releasing de-identified data is hard. We wanted to release something meaningful into the open as quickly as we could. So we chose person-course level data. We set the bar low for a first release to open the flow and get sharing started. We hope to release more kinds of open data, with more granularity in the future.
I think we’re the first folks to make de-id’d MOOC data available. We did not accomplish everything in the first step. We’re quite aware at how limited this is. But we started somewhere.
Does edX have click-stream data?
Yes. Tons of it. Being used in research. It’s a little messy, but we use it.
“I believe there is great difficulty getting non-event or non-aggregate data out of edX, at least in current forms.”
This is not true. All the HarvardX and MITx data is loaded loaded up in a MongoDB. People use it every day.
It wasn’t released yet, because releasing millions of rows is harder than releasing hundreds of thousands of rows. (Several folks from Harvard are currently at a meeting with folks from other universities figuring out how best to share it. http://www.politico.com/morningeducation/)
There are folks at Harvard, and even more folks at MIT who are using these event log data. Undergraduate Tommy Mullaney submitted a really cool thesis looking at student pathways through courses. It’ll get out.
Stanford has stronger machine learning/Bayesian learning analytics bench than Harvard does, and MIT does as well, so in the near term, expect more work from them along those lines.
My research presentation was not exhaustive, although generally belies my belief that we need advances in instrumentation and assessment. Fancy manipulations of of predictors (from the click stream) may be limited in value if we don’t have good measures of learning, or a rich understanding of the context of data. But I’m super excited, too, about people doing great work with the edX event log data, and it’ll get out.
I’m interested in helping people understand what we at HarvardX are up to. @bjfr on Twitter. [email protected] on email. If you have speculations about what the HarvardX research team is up to, feel free to ask.
Justin – thanks for the comment (note that I sent an email to Andrew, just FYI). First of all, I trust that my posts have been clear that I agree with you on the difficulty and value of releasing open data. I have seen other MOOC data released, but privately or only to select groups, so you are setting a very useful standard. And thanks for contact info.
The question is not really on having tons of click-stream data or having a database, but rather A) the ability to usefully pull it out in a usable format for analysis and B) the research on learner-centered patterns over time.
My follow-up questions for you that would help my understanding (and I’ll correct where needed):
– What data is available from edX based on learner patterns over time? I’m not looking for an exhaustive answer, but maybe at the level of your post on ‘person-click’ and ‘person-period’ data. Something like ‘the data is in a log file, which we parse to create these tables generally structured as such’ or ‘the data is already in separate person-period tables and we can reconstruct all learner activity by such and such’.
– Do you guys (HarvardX and MITx) have access to the full edX database in MongoDB, or some extract, and is that the same data access that other edX schools have?
– What research is likely to occur (and when) on edX data that looks at learner patterns over time (regardless of release of open data)? This might be the undergrad you mentioned, you guys or MIT or Stanford, but some sense of timeframe and subject would be useful to augment the 2013-14 presentation.
If these are easier to answer by phone, I’d be happy to call. Thanks in advance.
Hi Phil,
Thanks. I think my response bounced between addressing the comments as well as your post.
Here’s a few responses:
– What data is available from edX based on learner patterns over time? I’m not looking for an exhaustive answer, but maybe at the level of your post on ‘person-click’ and ‘person-period’ data. Something like ‘the data is in a log file, which we parse to create these tables generally structured as such’ or ‘the data is already in separate person-period tables and we can reconstruct all learner activity by such and such’
– Do you guys (HarvardX and MITx) have access to the full edX database in MongoDB, or some extract, and is that the same data access that other edX schools have?
HarvardX and MITx have a data-sharing agreement, and we have access to the data from our two institutions. edX sends each institution data, and we store that data in a secure database housed by Harvard’s Institute for Quantitative Social Science. X-consortium members only have access to their own data, which they can share bi-laterally, but no member has access to all edX data.
The most detailed description of all of edX data can be found at data.edx.org. The description of the tracking data is here: http://edx.readthedocs.org/projects/devdata/en/latest/internal_data_formats/tracking_logs.html.
We have the full set of events generated by users/registrants/students inside the HarvardX and MITx.
edX gives our institutions the full set of raw data, which sometimes we transform into derivative person-click, person-period, and person-course datasets.
– What research is likely to occur (and when) on edX data that looks at learner patterns over time (regardless of release of open data)? This might be the undergrad you mentioned, you guys or MIT or Stanford, but some sense of timeframe and subject would be useful to augment the 2013-14 presentation.
I can’t speak for MIT or Stanford researchers. Likely, they will do awesome stuff, and some of it for sure will be looking at people’s behavior at fine levels of granularity. At Harvard, we’re hiring several new people this summer, and who we hire will shape our future. We have some time-on-task research, we have some video viewing research, we’ve done some stuff with sample trajectories like Stanford folks did for Mike. This part of our work is emerging and evolving. It’s exciting to watch.
-Justin
Thanks Justin.
While tracking w/in a course is helpful, I believe that data as the system evolves is critical, as we have seen w/many other technologies, including digital. For example, the movement of educational institutions to offer credit on a routine basis and not just certificates, the rise of MOC’s (massive online courses-selective admissions) such as that of the Harvard Business School, the speed at which MOOC’s are appearing through providers other than Coursera or EdX and thus the experience factor of all parties. and (with current data) the evolution of MOOC’s in all dimensions (who provides, cost for providing and evolution of courses with the rise of the semantic web, and cost/evolution of the hardware for production and access).
As we see with the changes in publishing of research, there are significant changes such as a variety of Open Access models, the rise of Grey Literature, and access tools such as semantic enrichment, so goes the shifting arena of education itself as the two start to overlap (at least now nibbling at the edges)
It’s the system where MOOC’s in their current and future embodiment need to be considered in a dynamic context.
Hi Phil,
Thank you for pointing out the limits of aggregate data sets.
The OpenedX platform actually records user-centered and chronological interactions in the form of JSON logs.
Parsing these logs is indeed a difficult task, but massive efforts are underway at the Computer Science and Artificial Intelligence laboratory at MIT. This is a collective effort between us at MIT and Stanford, that is trying to get a handle over this data. Andreas Paepcke from Stanford has published scripts that populates a relational database from the OpenEdx JSON logs. (https://github.com/paepcke/json_to_relation) This is a first step, allowing easier exploration via SQL queries of raw OpenEdx data.
Pushing this work further, the ALFA group at MIT (which I am part of) completes a pipeline bridging OpenEdx logs and MOOCdb, an organized schema specifically designed to enable cross platform learning analytics. So your supposition below is very accurate :
” Something like ‘the data is in a log file, which we parse to create these tables generally structured as such’ ”
One can read about the effort and consult the dedicated wiki at http://moocdb.csail.mit.edu/. The current progress is also being documented and described at http://www.moocresearch.com/wp-content/uploads/2014/06/C9147_OREILLY_MRI_Report.pdf
Built on top of MOOCdb, an open source “feature factory” will enable the research community to share scripts that extract student behavioural variables. Variables that can then be used to construct fine grained data analytics models.
The team is hoping to do an open source release of the piping software in this quarter.
Quentin Agren
Quentin – thanks for the update and links to read more. I’m doing a follow-up post on this subject (unpacking log data, etc) and will likely quote / refer to your comments.