I have been meaning for some time to get around to blogging about the EDUCAUSE Learning Initiative’s (ELI’s) paper on a Next-Generation Digital Learning Environment (NGDLE) and Tony Bates’ thoughtful response to it. The core concepts behind the NGDLE are that a next-generation digital learning environment should have the following characteristics:
- Interoperability and Integration
- Personalization
- Analytics, Advising, and Learning Assessment
- Collaboration
- Accessibility and Universal Design
The paper also suggests that the system should be modular. They draw heavily on an analogy to LEGOs and make a call for more robust standards. In response, Bates raises three concerns:
- He is suspicious of a potentially heavy and bureaucratic standards-making process that is vulnerable to undue corporate influence.
- He worries that LEGO is a poor metaphor that suggests an industrialized model.
- He is concerned that, taken together, the ELI requirements for an NGDLE will push us further in the direction of computer-driven rather than human-driven classes.
As it happens, ELI’s vision for NGDLE bears a significant resemblance to a vision that some colleagues and I came up with ten years ago when we were trying to help the SUNY system find an LMS that would fit the needs of all 64 campuses,1 ranging from small, rural community colleges to R1 universities to medical and ophthalmology schools to a school of fashion. We got pretty deep into thinking about the implementation details, so it’s been on my mind to write my own personal perspective on the answers to Tony’s questions, based in large part on that previous experience. In the meantime, Jim Groom, who has made a transition from working at a university to working full-time at Reclaim Hosting, has written a series of really provocative and, to me, exciting posts on the future of the digital learning environment from his own perspective. Jim shares the starting assumption of the ELI and SUNY that a learning environment should be “learner-centric,” but he has a much more fully developed (and more radical) idea of what that really means, based on his previous work with A Domain of One’s Own. He also, in contrast to the ELI and SUNY teams, does not start from the assumption that “next-generation” means evolving the LMS. Rather, the questions he seems to be asking are “What is minimum amount of technical infrastructure required to create a rich digital learning environment?” and “Of that minimal amount of infrastructure we need, what is the minimal amount that needs to be owned by the institution rather than the learner?” I see these trains of thought emerging his posts on a university API, a personal API, and a syndication bus. What’s exciting to me about these posts is that, even though Jim is starting from a very different set of assumptions, he is also converging on something like the vision we had for SUNY.
In this post, I’m going to try to respond to both Tony and Jim. One of the challenges of this sort of conversation is that the relationship between the technical architecture and the possibilities it creates for the learners is complex. It’s easy to oversimplify or even conflate the two if we’re not very careful. So one of the things that I’m going to try to do here is untangle the technical talk from the functional talk.
I’ll start with Tony Bates’ concerns.
The Unbearable Heaviness of Standards
This is the most industry-talky part of the post, but it’s important for the later stuff. So if talk of Blackboard and Pearson sitting around a technical standards development table turns you off, please bear with me.
Bates writes,
First, this seems to be much too much of a top-down approach to developing technology-based learning environments for my taste. Standards are all very well, but who will set these standards? Just look at the ways standards are set in technology: international committees taking many years, with often powerful lobby groups and ‘rogue’ corporations trying to impose new or different standards.
Is that what we want in education? Or will EDUCAUSE go it alone, with the rest of the world outside the USA scrambling to keep up, or worse, trying to develop alternative standards or systems? (Just watch the European Commission on this one.) Attempts to standardize learning objects through meta-data have not had much success in education, for many good reasons, but EDUCAUSE is planning something much more ambitious than this.
Let me start by acknowledging, as somebody who has been involved in the sausage-making, that the technical standards development process is inherently difficult and fraught and that, because it is designed to produce a compromise that everybody can live with, it rarely produces a specification that anybody is thrilled with. Technical standards-making sucks, and its output often sucks as well. In fact, both process and output generally suck so badly that they collectively beg the question: Why would anyone ever do it? The answer is simple: Standards are usually created when the pain of not having a standard exceeds the pain of creating and living with one.
One of the biggest pains driving technical standards-making in educational technology has been the pain of vendor lock-in. Back in the days when Blackboard owned the LMS market and the LMS product category pretty much was the educational technology market, it was hard to get anyone developing digital learning tools or digital content to integrate with any other platform. Because there were no integration standards, anyone who wanted to integrate with both Blackboard and Moodle would have to develop that integration twice. Add in D2L and Sakai—this was pre-Canvas—and you had four times the effort. This is a problem in any field, but it’s particularly a problem in education because neither students nor courses are widgets. This means that we need a ton of specialized functionality, down to a very fine level. For example, both art historians and oncologists need image annotation tools to teach their classes digitally, but they use those tools very differently and therefore need different features. Ed tech is full of tiny (but important) niches, which means that there are needs for many tools that will make nobody rich. You’re not going to see a startup go to IPO with their wicked good art history image annotation tool. And so, inevitably, the team that develops such a tool will start small and stay small, whether they are building a product for sale, an open source project, or some internal project for a university or for their own classes. Having to develop for multiple platforms is just not feasible for a small team, which means the vast majority of teaching functionality will be available only on the most widely adopted platform. Which, in turn, makes that platform very hard to leave, because you’d also have to give up all those other great niche capabilities developed by third parties.
But there was a chicken-and-egg problem. To Tony’s point about the standards process being prone to manipulation, Blackboard had nothing to gain and a lot to lose from interoperability standards back when they dominated the market. They had a lot to gain from talking about standards, but nothing to gain (and a lot to lose) by actually implementing good standards. In those days, the kindest interpretation of their behavior in the IMS (which is the main technical standards body for ed tech) is that standards-making was not a priority for them. A more suspicious mind might suspect that there were times when they actively sabotaged those efforts. And they could, because a standard that wasn’t implemented by the platform used by 70% of the market was not one that would be adopted by those small tool makers. They would still have to build at least two integrations—one for Blackboard and one for everyone else. Thankfully, two big changes in the market disrupted this dynamic. First, Blackboard lost its dominance, thanks in part to the backlash among customers against just such anti-competitive behavior. It is no coincidence that then-CEO Michael Chasen chose to retain Ray Henderson, who was known for his long-standing commitment to open standards (and…um…actually caring about customer needs) right at the point when Blackboard backlash was at its worst and the company faced the probability of a mass exodus as they killed off WebCT. Second, content-centric platforms became increasingly sophisticated with consequent increasingly sophisticated needs for integrating other tools. This was driven by the collapse of the textbook publishers’ business model and their need to find some other way to justify their existence, but it was a welcome development for standards both because it brought more players to the table and because the world desperately needed (and still needs) alternative visions to the LMS for a digital learning environment, and the textbook publishers have the muscle to actually implement and drive adoption of their own visions. It doesn’t matter so much whether you like those visions or the players who are pushing them (although, honestly, almost anything would be a welcome change from the bento box that was and, to a large degree, still is the traditional LMS experience). What mattered from the standards-making perspective is that there were more players who had something to prove in the market and whose ideas about how niche functionality should integrate with the larger learning experience that their platform affords was not all the same. As a result, we are getting substantially richer and more polished ed tech integration standards more quickly from the IMS than we were getting a decade ago.
Unfortunately, the change in the market only helps with one of the hard problems of technical standards-making in ed tech. Another one, which Bates alludes to with his comment about failed efforts to standardize metadata for learning objects, is finding the right level of abstraction. There are a lot of reasons why learning objects have failed to gain the traction that advocates had hoped, but one good one is that there is no such thing as a learning object. At least, not one that we can define generically. What is it that syllabi, quizzes, individual quiz questions, readings, videos, simulations, week-long collections of all these things (or “modules”), and 15-week collections of these things (or “courses”) have in common? It is tempting to pretend that all of these things are alike in some fundamental way so that we can easily reuse them and build new things with them. You know…like LEGOs. If they were, then it would make sense to have one metadata standard to describe them all, because it would mean that the main challenge of building a new course out of old pieces would be finding the right pieces, and a metadata standard can help with that.
Alas.
Folks who are non-technical tend to think of software as a direct implementation of their functional needs, and their understanding of technical standards flows from that view of the world. As a result, it’s easy to overgeneralize the lesson of the learning object metadata standards failures. But the history of computing is one of building up successive layers of abstraction. For example, TCP/IP is a low-level technical standard that enables internet servers to connect to and communicate with each other, whether that communication takes the form of sending email, transferring a file, or looking up the address of a web site. Most of us don’t know about or care about what sorts of connections TCP/IP allows or doesn’t allow. At our level, it is indistinguishable from LEGOs in the sense tha we see these pieces fitting together generically and we don’t see a need for them to do anything else. But the programmers who built TCP/IP implemented it on top of the C programming language (which was standard in the informal sense that eventually became a Standard(TM) in the formal sense), which compiled to a number of different machine languages for different computer chips, making those chips more like LEGOs. Then other programmers created HTML and Javascript as a abstraction layers on top of TCP/IP, making web pages like LEGOs in the sense that any web server can serve any standards-conformant web page and any browser can read any such web page. From here, higher layers of abstraction get dicier, which is probably why we don’t have many higher-level Standards(TM). Instead, we start getting into things called “libraries” and “frameworks”. These are bits of code that are re-usable by enough developers that they are worth sharing and adopting, but not so much that they are worth going through the pain of formal standards development or become universal through some other means. And then, of course, there is just a vast amount of development on the web that is individual to the project and cannot be standardized, whether formally or informally. If you try to standardize that which is not standard, chances are that your “standard” will remain pretty non-standard.
So there is a generic danger that if we try to build a standard at the wrong level of abstraction, we will fail. But in education there is also the danger that we will try to build at the wrong level of abstraction and succeed. What I mean by this is we will enshrine a limited or even stunted vision of what kinds of teaching and learning a digital learning environment should support into the fundamental building blocks that we use to create new learning environments and learning experiences.
In What Sense Like LEGOs?

To wit, Bates writes:
A next generation digital learning environment where all the bits fit nicely together seems far too restrictive for the kinds of learning environments we need in the future. What about teaching activities and types of learning that don’t fit so nicely?
We need actually to move away from the standardization of learning environments. We have inherited a largely industrial and highly standardized system of education from the 19th century designed around bricks and mortar, and just as we are able to start breaking way from rigid standardization EDUCAUSE wants to provide a digital educational environment based on standards.
I have much more faith in the ability of learners, and less so but still a faith in teachers and instructors, to be able to combine a wide range of technologies in the ways that they decide makes most sense for teaching and learning than a bunch of computer specialists setting technical standards (even in consultation with educators).
Audrey Watters captured the subtlety of this challenge beautifully in her piece on the history of LEGO Mindstorms:
In some ways, the educational version of Mindstorms faces a similar problem as it struggles to balance imagination with instructions. As the product have become more popular in schools, Lego Education has added new features that make Mindstorms more amenable to the classroom, easier for teachers to use: portfolios, curriculum, data-logging and troubleshooting features for teachers, and so on.
“Little by little, the subversive features of the computer were eroded away. Instead of cutting across and challenging the very idea of subject boundaries, the computer now defined a new subject; instead of changing the emphasis from impersonal curriculum to excited live exploration by students, the computer was now used to reinforce School’s ways. What had started as a subversive instrument of change was neutralized by the system and converted into an instrument of consolidation.” – Seymour Papert, The Children’s Machine
That constructionist element is still there, of course – in Lego the toy and in Lego Mindstorms. Children of all ages continue to build amazing things. Yet as Mindstorms has become a more powerful platform – in terms of its engineering capabilities and its retail and educational success – it has paradoxically perhaps also become a less playful one.
There is a fundamental tension between making something more easily adoptable for a broad audience and making it challenging in the way that education should be challenging, i.e., that it is generative and encourages creativity (a quality that Amy Collier, Jen Ross, and George Veletsianos have started calling “not-yetness“). I don’t know about you, but when I was a kid, my LEGO kits didn’t look like this:

If I wanted to build the Millennium Falcon, I would have to figure out how to build it from scratch, which meant I was more likely to decide that it was too hard and that I couldn’t do it. But it also meant I was much more likely to build my own idea of a space ship rather than reproducing George Lucas’ idea. This is a fundamental and inescapable tension of educational technology (as well as the broad reuse or mass production of curricular materials), and it increases exponentially when teachers and administrators and parents are added as stakeholders in the mix of end users. But notice that, even with the real, analog-world LEGO kits, there are layers of abstraction and standardization. Standardizing the pin size on the LEGO blocks is generative because it suggests more possibilities for building new stuff out of the LEGOs. Standardizing the pieces to build one specialized model is reductive because it suggests fewer possibilities for building new stuff out of the LEGOs. To find ed tech interoperability standards that are generative rather than reductive, we need to first find the right level of abstraction.
What Does Your Space Ship Look Like?
This brings us to Tony Bates’ third concern:
I am becoming increasingly disturbed by the tendency of software engineers to force humans to fit technology systems rather than the other way round (try flying with Easyjet or Ryanair for instance). There may be economic reasons to do this in business enterprises, but we need in education, at least, for the technology to empower learners and teachers, rather than restrict their behaviour to fit complex technology systems. The great thing about social media, and the many software applications that result from it, is its flexibility and its ability to be incorporated and adapted to a variety of needs, despite or maybe even because of its lack of common standards.
When I look at EDUCAUSE’s specifications for its ‘NGDLE-conformant standards’, each on its own makes sense, but when combined they become a monster of parts. Do I want teaching decisions influenced by student key strokes or time spent on a particular learning object, for instance? Behind each of these activities will be a growing complexity of algorithms and decision-trees that will take teachers and instructors further way from knowing their individual students and making intuitive and inductive decisions about them. Although humans make many mistakes, they are also able to do things that computers can’t. We need technology to support that kind of behaviour, not try to replace it.
I read two interrelated concerns here. One is that, generically speaking, humans have a tendency to move too far in the direction of standardizing that which should not be standardized in an effort to achieve scalability of efficiency or one of those other words that would have impressed the steel and railroad magnates of a hundred years ago. This results in systems that are user-unfriendly at best and inhumane at worst. The second, more education-specific concern I’m hearing is that NGDLE as ELI envisions it would feed the beast that is our cultural mythology that education can and should be largely automated, which is pretty much where you arrive if you follow the road of standardization ad absurdam. So again, it comes down to standardizing the right things at the right levels of abstraction so that the standards are generative rather than reductive.
I’ll give an example of a level of ed tech interoperability that achieves a good level of LEGOicity.2 Whatever digital learning environment you choose, whether it’s next-generation, this-generation, last-generation, or whatever-generation, there’s a good chance that you are going to want it to have some sense of “class-ness”, by which I mean that you will probably want to define a group of people who are in a class. This isn’t always true, but it is often true. And once you decide that you need that, you then need to specify who is in the class. That means, for every single class section that needs a sense of group, you need to register those users in the new system. If the system supports multiple classes that the students might be in (like an LMS, for example), then you’ll need unique identifiers for the class groups so that the system doesn’t get them mixed up, and you will also need human-readable identifiers (which may or may not be unique) so that the humans don’t get them mixed up and get lost in the system. Depending on the system, you may also want it to know when the class starts and ends, when it meets, who the teacher is, and so on. Again, not all digital learning environments require this information, but many do, including many that work very differently from each other. Furthermore, trying to move this information manually by, for example, asking your students to register themselves and then join a group themselves is…challenging. It makes sense to create a machine-to-machine method for sharing this information (a.k.a. an application programming interface, or API) so that the humans don’t have to do the tedious and error-prone manual work, and it makes sense to have this API be standard so that anybody developing a digital learning environment or learning tool anywhere can write one set of integration code and get this information from the relevant university system that has it, regardless of the particular brand or version of the system that the particular university is using. The IMS actually has two different standards—LIS and LTI—that do subsets of this sort of thing in different ways. Each one is useful for a particular and different set of situations, so it’s rare that you would be in a position of having to pick between the two. In most cases, one will be obviously better for you than the other. The existence and adoption of these standards are generative, because more people can build their own tools, or next-generation digital learning environments, or whatever, and easily make them work well for teachers and students by saving them from that tedious and frustrating registration and group creation workflow.
Notice the level of abstraction we are at. We are not standardizing the learning environment itself. We are standardizing the tools necessary for developers to build a learning environment. But even here, there are layers. Think about your mobile phone. It takes a lot of people with a lot of technical expertise a lot of time to build a mobile phone operating system. It takes a single 12-year-old a day to build a simple mobile phone app. This is one reason why there are only a few mobile phone operating systems which all tend to be similar while there are many, many, mobile apps that are very different from each other. Up until now, building digital learning environments has been more like building operating systems than like building mobile apps. When my colleagues and I were thinking about SUNY’s digital learning environment needs back in 2005, we wanted to create something we called a Learning Management Operating System (LMOS), but not because we thought that either learning management or operating systems were particularly sexy. To the contrary, we wanted to standardize the unsexy but essential foundations upon which a million billion sexy learning apps could be built by others. Try to remember what your smart phone was like before you installed any apps on it. Pretty boring, right? But it was just the right kind of standardized boring stuff that enabled such miracles of modern life as Angry Birds and Instragram. That’s what we wanted, but for teaching and learning.
Toward University APIs
Let’s break this down some more. Have you ever seen one of these sorts of prompts on your smart phone?
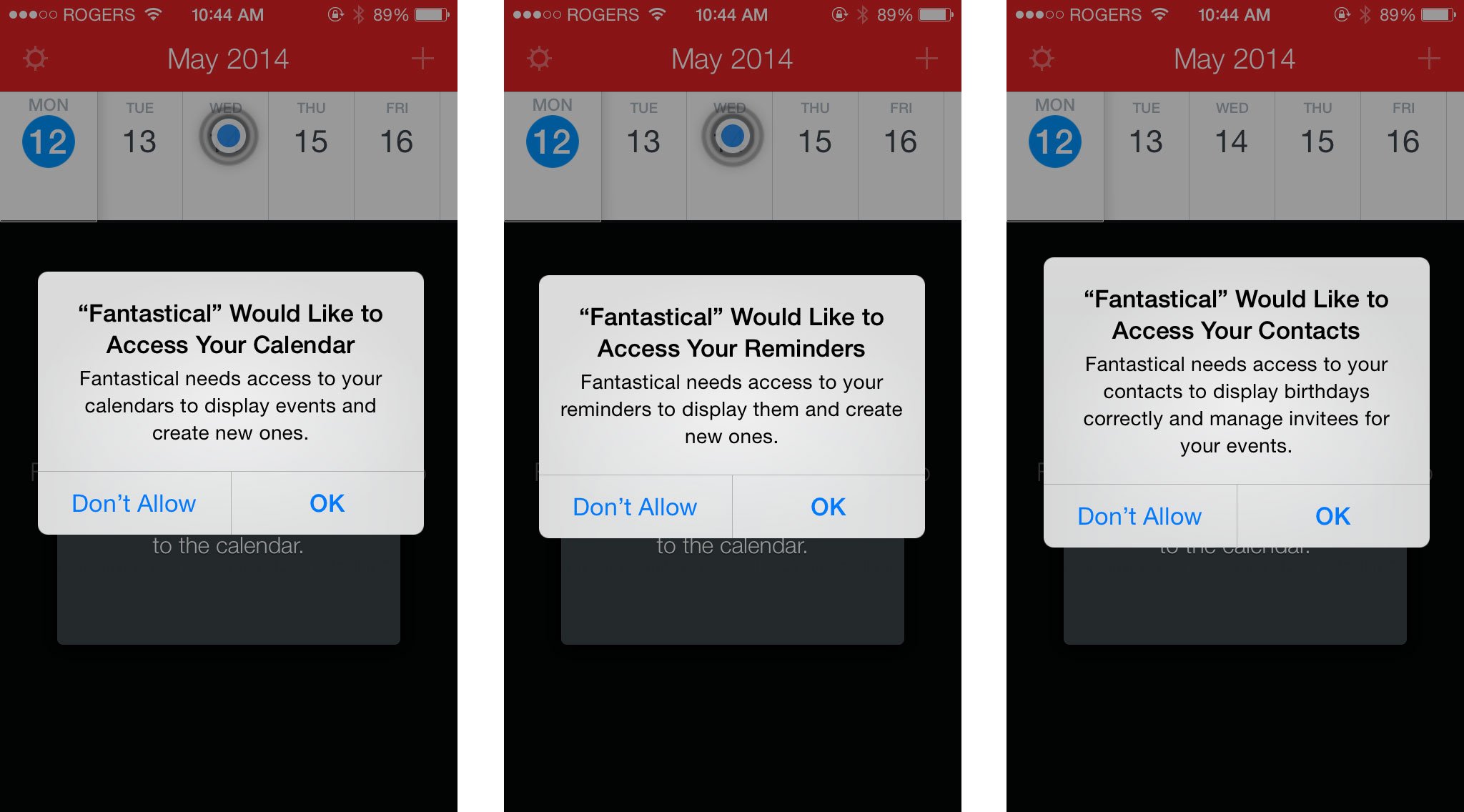
I bet that you have. This is one of those incredibly unsexy layers of standardization that makes incredibly sexy things happen. It enables my LinkedIn Connected app to know who I just met with and offer to make a connection with them. It lets any new social service I join know who I already know and therefore who I might want to connect with on that service. It lets the taxicab I’m ordering know where to pick me up. It lets my hotel membership apps find the nearest hotel for me. And so on. But there’s something weird going on in this screen grab. Fantastical, which is a calendar app, is asking permission to access my calendar. What’s up with that?
Apple provides a standard Calendar app that is…well…not terribly impressive. But that’s not what this dialog box is referring to. Apple also has an underlying calendaring API and data store, which is confusingly also named Calendar. It is this latter piece of unsexy but essential infrastructure that Fantastical is asking to access. It is also the unsexy piece of infrastructure that makes all the scheduling-related sexiness happen across apps. It’s the lingua franca for scheduling.
Now imagine a similar distinction between a rather unimpressive Discussions app within an LMS and a theoretical Discussions API in an LMOS. Most discussion apps have certain things in common. There are posts by authors. There are subjects and bodies and dates and times to those posts. Sometimes there are attachments. There are replies which form threads. Sometimes those threads branch. Imagine that you have all of that abstracted into an API or service. You could do a lot of things with it. For starters, you could build a different or better discussion board, the way Fantastical has done on top of Apple’s Calendar API. It could be a big thing that has all kinds of cool extra features, or it could be a little thing that, for example, just lets you attach a discussion thread anywhere on any page. Maybe you’re building an art history image annotation app and want to be able to hang a discussion thread off of particular spots on the image. Wouldn’t it be cool if you didn’t have to build all that discussion stuff yourself, but could just focus on the parts that are specific to your app? Maybe you’re not building something that needs a discussion thread at all but rather something that could use the data from the discussions app. Maybe you want to build a “Find a Study Buddy” app, and you want that app to suggest people in your class that you have interacted with frequently in class discussions. Or maybe you’re building an analytics app that looks at how often and how well students are using the class discussions. There’s a lot you could do if this infrastructure were standardized and accessible via an API. An LMOS is really a university API for teaching- and learning-relevant data and functionality, with a set of sample apps built on top of that API.
What’s valuable about this approach is that it can support and enable many different kinds of digital learning environments. If you want to build a super-duper adaptive-personalized-watching-every-click thing, an LMOS should make that easier to do. If you want to build a post-edupunk-open-ed-only-nominally-institutional thing, then an LMOS should make it easier to do that too. You can build whatever you need more quickly and easily, which means that you are more likely to build it. Done right, an LMOS should also support the five attributes that ELI is calling for:
- Interoperability and Integration
- Personalization
- Analytics, Advising, and Learning Assessment
- Collaboration
- Accessibility and Universal Design
An LMOS-like infrastructure doesn’t require any of these things. It doesn’t require you to build analytics, for example. But by making the learning apps programmatically accessible via APIs, it makes analytics feasible if analytics are what you want. It is the roughly the right level of abstraction.
It is also roughly where we are headed, at least from a technical perspective. Returning to the earlier question of “at what price standards,” I believe that we have most or all of the essential technical interoperability standards we need to build an LMOS right now. Yes, there are a couple of interesting standards-in-development that may add further value, and yes, we will likely discover further holes that need to be filled here and there, but I think we have all the basic parts that we need. This is in part due to the fact that, with IMS’s new Caliper standard, we have yet another level of abstraction that makes it very flexible. Building on the previous discussion service example, Caliper lets you define a profile for a discussion, which is really just a formalization of all the pieces that you want to share—subject, body, author, time stamp, reply, thread, etc. You can also define a profile for, say, a note-taking app that re-uses the same Caliper infrastructure. If you come up with a new kind of digitally mediated learning interaction in a new app, you can develop a new Caliper profile for it. You might start by developing it just for your own use and then eventually submit it to the IMS for ratification as an official standard when there is enough demand to justify it. This also dramatically reduces the size of the negotiation that has to happen at the standards-making table and therefore improves both speed and quality of the output.
Toward a Personal API
I hope that I have addressed Tony Bates’ concerns, but I’m pretty sure that I haven’t gotten to the core of Jim Groom’s yet. Jim wants students to own their learning infrastructure, content, and identity as much as possible. And by “own,” he means that quite literally. He wants them to have their own web domains where the substantial majority of their digital learning lives resides permanently. To that end, he has started thinking about what he calls a Personal API:
[W]hat if one’s personal domain becomes the space where students can make their own calls to the University API? What if they have a personal API that enables them to decide what they share, with whom, and for how long. For example, what if you had a Portfolio site with a robust API (which was the use case we were discussing) that was installed on student’s personal domain at portfolio.mydomain.com, and enabled them to do a few basic things via API:
- It called the University API and populated the students classes for that semester.
- It enabled them to pull in their assignments from a variety of sources (and even version them).
- it also let them “submit” those assignment to the campus LMS.
- This would effectively be enabling the instructor to access and provide feedback that the student would now have as metadata on that assignment in their portfolio.
- It can also track course events, discussions, etc.
This is very consistent with the example I gave in my 2005 blog post about how a student’s personal blog could connect bi-directionally with an LMOS:
Suppose that, in addition to having students publish information into the course, the service broker also let the course publish information out to the student’s personal data store (read “portfolio”). Imagine that for every content item that the student creates and owns in her personal area–blog posts, assignment drafts in her online file storage, etc.–there is also a data store to which courses could publish metadata. For example, the grade book, having recorded a grade and a comment about the student’s blog post, could push that information (along with the post’s URL as an identifier) back out to the student’s data store. Now the student has her professor’s grade and comment (in read-only format, of course), traveling with her long after the system administrator closed an archived the Psych 101 course. She can publish that information to her public e-portfolio, or not, as she pleases.
Fortuitously, this vision is also highly consistent with the fundamental structure that underlies IMS Caliper. Caliper is federated. That is, it assumes that there are going to be different sources of authority for different (but related) types of content, and that there will be different sharing models. So it is very friendly to world in which students own some data and universities own other data and could provide the “facade” necessary for the communication between the two world. So again, we have roughly the right level of abstraction to be generative rather than reductive. Caliper can support both a highly scaffolded and data-driven adaptive environment and a highly decentralized and extra-institutional environment. And, perhaps best of all, it lets us get to either incrementally by growing an ecosystem piece by piece rather than engineering a massive and monolithic platform.
Nifty, huh?
Believe it or not, none of this is the hard part. The hard part is the cultural and institutional barriers that prevent people from demanding the change that is very feasible from a technical perspective. But that’s another blog post (or fifty) for another time.
[…] By Michael FeldsteinMore Posts (1030) I have been meaning for some time to get around to blogging about the EDUCAUSE Learning Initiative’s (ELI’s) paper on a Next-Generation Digital Learning Environment (NGDLE) and Tony Bates’ thoughtful response to it. The core … Continue reading → […]